现在为了处理骨架数据,往往使用的方法是图卷积。图卷积一开始是使用于社交网络领域,用来处理一些非欧式空间的信息,这样定义的点为实体,边则是实体之间的关系,通常是异构的。而在ST-GCN中,可以说是首次成功将(2018)图卷积应用到基于骨架的行为识别中,这种引用是直觉上的,因为骨架数据中,骨骼的端点就可以看成是图中的点,然后边就是他们的关系(相邻与否)。用一个邻接矩阵就可以描述关键点之间的关系。这里我的记录顺序就从一篇知乎大神写的理解图卷积的文章出发,然后解读ST-GCN,接着是ST-GCN的改进文章,2s-AGCN。
一.如何理解图卷积
参考:https://www.zhihu.com/question/54504471/answer/611222866
我看了几篇关于图卷积的简单解读,感觉这篇是最好理解的,作者是从空域的角度去解读图卷积的操作的。以下内容就摘自该文章。
图卷积的核心思想是利用边的信息(邻接矩阵),对节点信息进行聚合从而生成新的节点表示。
上述核心思想贯穿整个逻辑线,其他的角度我们暂且不去分析,例如利用节点生成边表示之类的。就像电脑一开始也不是这么小的,我们一步一步看最后的图卷积公式是怎么演化来的吧。首先有几个符号记一下:

1.平均法
比如说,我们要计算我之后的工资水平是怎样的。这个要怎么计算呢?最简单的想法就是看看你周围的人工资是怎样的,也就是直接把和我关系最亲密(相邻)的人的工资相加后,就可以衡量我的工资水平。也就是$$aggtrgate(X_i) = \sum_{j\in neighbor(i)}A_{ij}X_j$$
平均数只要对加和的系数进行归一化就行了,这里就不提了。
2.加权平均法
前面提到的和我关系最亲密(相邻)的人,实际上这里的关系量化得还不够细,人之间的亲密度是不同的,也就是我们还得考虑边的权重,我们只需要把无权图变成有权图就可以啦。这里稍微拓展一下就是一个工作了,就是如何构建有权图(比如节点间的相似度之类的)
$$aggtrgate(X) = AX$$
这里的A是有权图(就不是简单的0和1)
3.添加自环
当然我们不能简单地考虑朋友的工资,我们还得考虑我们个人的经历和努力程度,这些都和我们的工资息息相关。所以就是添加一个自环就行。也就是我们自己和自己也有关系,之前是设为没有关系的。
$$aggtrgate(X) = (A+I)X$$
4.另一种思路
有的时候别人对我的工资并不感兴趣,而是想知道我的真正的底子是怎么样的,这时候要考察我的工资和朋友们工资的差距。也就是想知道一个差分的值。这里就有涉及到拉普拉斯矩阵的概念啦:$D_{ii}=\sum_{j\in N}A_{ij}$
$$
\begin{aligned}
\operatorname{diff}(X) &=(D-A) X \
&=D X-A X \
\operatorname{diff}\left(X_{i}\right) &=\sum_{j \in N} A_{i j} X_{i}-\sum_{j \in N} A_{i j} X_{j} \
&=\sum_{j \in N} A_{i j}\left(X_{i}-X_{j}\right)
\end{aligned}
$$
上述式子就是计算差分的。可以看出来就是把自己的工资依次和邻接点的工资相减,然后再累加起来。
###4.1.归一化
无论是那种方法都没有提到归一化的问题,这个归一化很重要,因为有的交际花可能朋友圈质量不咋滴,但是它广啊,这样累加起来,那结果也是了不得的。严谨来说,这会导致哪些比较孤僻的大佬特征就比较小,哪些离群近的特征就比较大,这样就违背我们找金女婿的初衷了。哈哈哈哈哈。
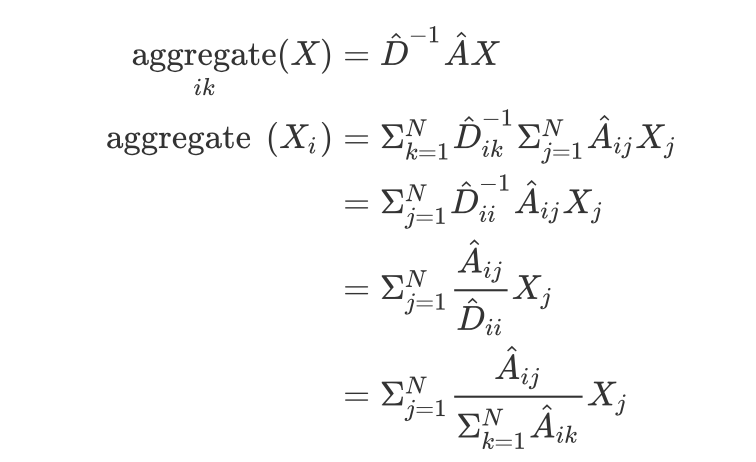
这里的公式感觉还是有点怪怪的,但是你只要知道这个操作是为了归一化就行了。
4.3.对称归一化
为了解决平均的问题,我们不仅要知道我们的平均,还得知道我们最亲密的人的平均,这样才是最准确的。因为我们的朋友也是各有各的性格的嘛。比如一个程序员,他的朋友可能有绿茶婊,我们就要剔除这种不好的影响。(这种朋友影响我们对该程序员工资的预测),所以就有:
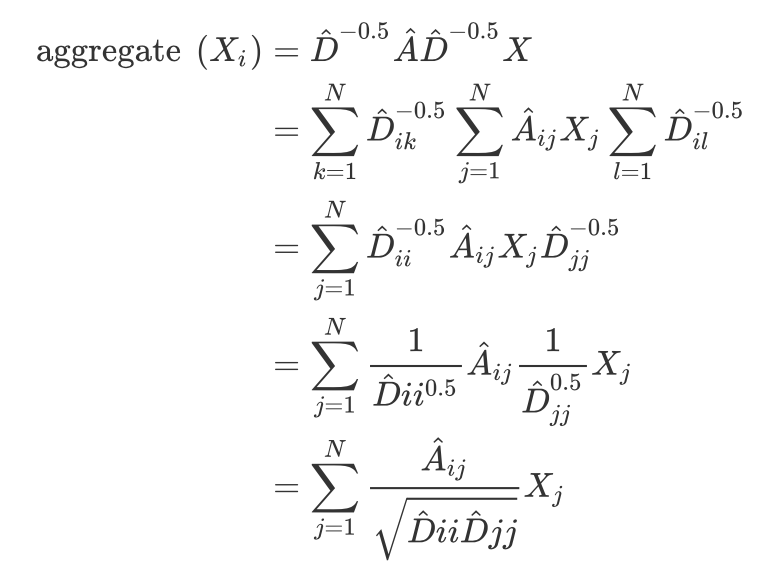
这样就同时考虑到了本身和邻接点的平均情况了。但是这上面的公式都没有涉及到参数啊,我们在学CNN网络的时候一般网络都是有参数去学习不是嘛?(这里我们考虑邻接矩阵是无权重的)。所以最后还得给他一个权重矩阵去学习:
$\hat{D}^{-0.5} \hat{A} \hat{D}^{-0.5} \Theta$
总结
回想一下一开始的引用文,图卷积就是信息聚合的一种方法,回想一下二维卷积不也是在做这种事情吗,对感受野做信息的聚合,将浅层的信息聚合成深层的东西,而网络的不同无非改变聚合的方式罢了。
二.解读ST-GCN
这篇论文很经典,我看过很多次了。每次都可以收获到不一样的东西。
它的思路其实也很简单,就是按人体的物理构造去建图,然后用前面我们的图卷积的方法去对骨架数据做消息聚合,然后在最后用全局池化层来处理长度不定的输入序列。我这里主要侧重去讲图卷积部分,具体的论文细节解读之后我会再整理。
1.图的构建
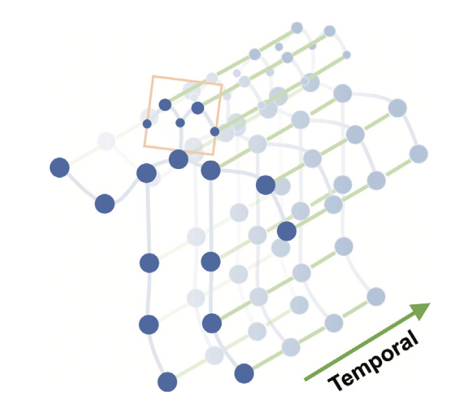
这里用时空图来表示N个关节点与T帧的人体骨架序列中空间与时间的连接关系。
2.权重函数
这个部分是最关键的,也是ST-GCN的创新点。在二维卷积中,我们的权重函数是一个匹配的可以按照空间顺序(矩阵)建立索引来进行按元素的乘法,但是对图就没办法了,这里是采用了映射的策略,就是将某一类点统一用某一个权重值。这里用了三种对节点的分区策略:单标签、距离分区以及空间结构分区(离心和向心)。最后一种的公式表示为:
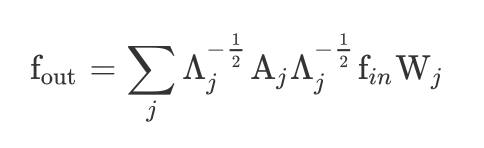
这里的j有三个。分析一下这个公式,输出等于归一化的邻接矩阵(自相关的)去点乘输入矩阵然后再点乘一个权重矩阵。
然后还有一个权重就是TCN的权重了,这里和二维卷积类似,就是有一个对应的关系:(这里是通道数(特征维度)改变的过程)

三.解读2s-AGCN
因为项目中有使用到这篇论文中的方法,所以必须很熟悉地掌握。这篇是ST-GCN的改进论文,所以只需要额外掌握一些东西就行,也就是本文的主要贡献点,一共就两个,一个是自适应图卷积网络,还有一个是双流框架,使用了骨架(二阶数据)数据。
1.自适应图卷积
就是改变原来的只有表示物理结构的邻接矩阵,从一个变成了三个。
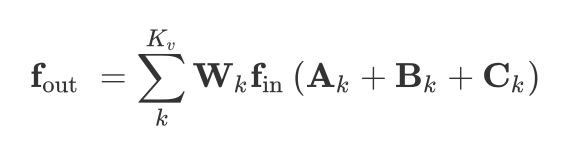
A:和ST-GCN的一样,不多说了,就是归一化的N*N的邻接矩阵。
B:也是一个N*N的邻接矩阵,但是他的值是没有限制的,和其他参数一起参数化和优化,矩阵起到注意机制的作用。
C:是一个数据相关图。为每个样本学习一个唯一的图。为了确定两个顶点之间是否存在连接以及强度,使用归一化的嵌入高斯函数来计算两个顶点的相似性。这里就是用了两个映射函数,把两个输入转换一下,然后用向量内积算一下,然后再将矩阵归一化。就是我们要的矩阵了(图):
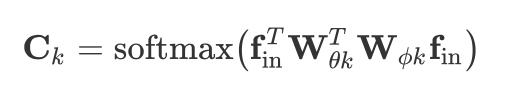
作者没有直接用Bk和Ck去替换Ak,而是将他们添加到里面,Bk值和两个嵌入函数参数初始化为0,这样可以在不降低原有性能的基础上增强模型的灵活性(Resnet)。
2.双流网络
这里只要知道骨骼怎么得到的就好了,因为后面的输入就是一个骨骼对应一个节点,后面的细节都是一样的。每个骨骼都是由两个关节绑定的,我们定义靠近骨骼重心的关节是源关节,远离重心的关节是目标关节,每个骨骼的表示是从源关节指向目标关节。我们为每个骨骼指定一个唯一的目标关节,关节的数量比骨骼数量多一个,中心关节没指定给任何骨骼,所以我们添加一个值为0的空骨骼。这样就一一对应起来的。
