这是一块难啃的骨头,我实在啃不动。整体的算法逻辑我还是大致了解了,主要是涉及到具体的案例还不是很清楚,还有就是收敛性证明不是很清楚,之后再看的话,会回来补充。
1.什么是EM算法?
EM算法是极大似然估计(MLE)的延伸版本。MLE就是求解使得出现可观测(无隐含变量)样本集的概率最大的模型参数。那假如样本集有隐含变量怎么办呢?也就是说这个样本属于哪个概率模型我们不知道,我们就无法给出准确概率表达式,这样MLE的计算也就无从谈起了。所以我们需要解决这个不确定性的问题,解决的方法就是EM算法。题外话,MLE往另一个方向拓展就是最大后验概率估计(MAP)和贝叶斯估计,我还没复习到,就不拓展了。
2.为什么可以用EM算法解决隐含变量问题?
这是因为EM算法通过构造一个关于隐含变量的函数,并利用了Jesen不等式的性质,得出当这个隐含变量为隐含变量关于样本的条件概率时,可以构造出一个原目标函数的下界,这样求解原目标函数的极大值就转换成求解下界函数的极大值的问题。而这个下界是可以通过MLE进行求解的。后面通过迭代来不断提高这个下界的极大值来间接提高原目标函数的极大值,当这个极大值不变时,我们就得到了原目标函数的局部最大值。(为什么是局部最大值?,有点像梯度下降算法,一旦落入到某个鞍点时候,没有梯度就跳不出这个鞍点,而这个鞍点可能就只是一个极值。看下图。)
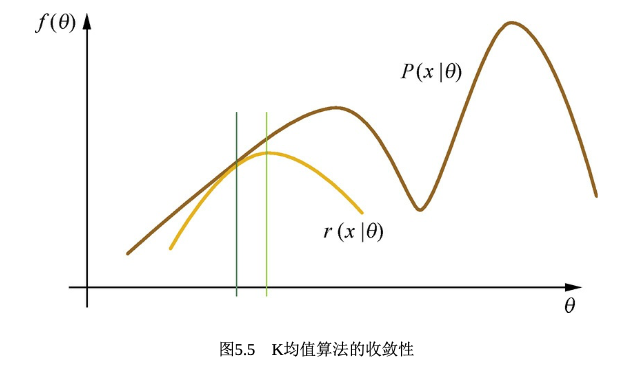
3.怎么推导EM?
上面一个问题中,我们说到,EM算法实质上是一个迭代算法,使用Jesen不等式的定义,通过不断构造局部下界,求这个下界的极大值来求解目标函数的极大值。那整体推导过程是怎么样的?我在知乎上看到一篇推导过程非常详细的回答,我直接给链接了,我这里不赘述了。彭一洋的回答
4.EM算法具体有哪些应用?
待补充···
