开新坑,主要记录在直播课中一些比较重要的信息,顺便梳理一下主要的思路。
这一篇记录的是开营仪式,主要分两个部分:介绍Kaggle,时序建模通用流程,介绍赛题以及baseline思路
1.Kaggle
kaggle就是一个平台,里面有很多比赛,和数据科学比较相关,是google公司的。M5属于featured类的比赛。
Kaggle比赛有金、银和铜的奖牌。称号的话有GM、M、EX、Con、Nov和User。
在一个比赛界面中,比较重要的是Notebooks和Discussion以及Leaderboard。在打比赛的时候应该经常Discussion里面看看。
A/B榜:就是验证集和测试集。
2.时序建模的通用流程
1.EDA(数据分析)
2.特征工程
3.模型训练(多数使用机器学习的方法)
4.线下验证
时间建模方案:
规则建模、自回归建模、趋势拟合、机器学习建模、深度学习建模
(高分的方案一定是复合的方案!!!!)
3.M5赛题背景介绍
M5就是一个预测销售量(未来28天)的问题。
一共有3张表(销量和店铺、所在州的信息的主要表、节假日信息表、销售价格表)。
A榜:1913天数据预测后28天数据(2016-04-25 to 2016-05-22)
B榜:1941天数据预测后28天数据 (2016-05-23 to 2016-06-19)
ps:B榜6月1日公布,然后6月30日截止。
样本的组成:(42840)
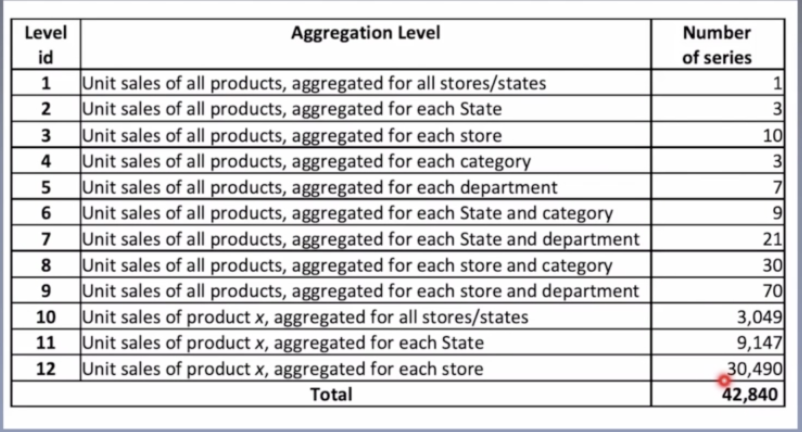
其中30490条是某商品在某家商店中的销量,其他则是由这30490条的信息聚合得到的时间序列。
评估指标WRMSSE
Weighted Root Mean Squared Scaled Error(WRMSSE)

左边理解一下:下面的分母是训练集的标签(销售量)差值,n是训练集的大小,h是要预测的天数(28天)。分子就是真实值和预测的差值。
右边的理解一下:因为每个时间序列都有一个预测,总共有42840个时间序列,所以去一个期望,这里的w的计算方式是看每个时间序列后28天的销售额的占比与level(看前面那张图)的倒数相乘(分母是30490个个样本的后28天的销售额的总和)。w的累加为1。
目标函数和损失函数是不一样的,在比赛当中找一个好的损失函数非常的重要。
4.baseline思路介绍
1.数据分析EDA
总的销量有年周期性,趋势向上。
数据的分布不是高斯分布,是柏松分布。
特征构造用抽取窗口特征:
1.前7天
2.前28天
3.前7天均值
4.前28天均值
或者关联其他维度的信息:日期、价格等
###baseline的代码分析
传统的时间序列预测模型无法拟合趋势。这是因为基模型是CART决策树,输出的范围限定在了训练集的范围内。所以我们最后的预测值的出来后还要去乘以一个系数。(这个系数可以是超参数,也可以重新另外训练一个趋势模型来得到,后面的方法会好一点。但是在baseline中是用前面一种方法。)
