1.时间序列基础
分成点预测和区间预测。
点预测是准确(定量)预测,区间预测是有置信度的预测。
什么时间序列可预测?
1.我们知道哪些因素会影响时间序列。
2.有大量的数据是可用的。
3.预测不会反向影响我们试图预测的事物。(能够预测股票的万能机器)
什么时间序列可定量建模?
1.关于过去的数据是可用的。
2.有理由假设过去的一些模式会在未来延续下去。

建模方式
1.回归模型
当下时刻的预测变量由当下时刻的其他变量所决定。
这里的误差包含两部分,一部分是随机波动,另一部分是没有被其他变量所解释的信息。
2.自回归模型
对未来的预测是基于变量的过去值,而不是基于可能影响系统的外部变量。“误差”项允许
随机波动和不包含在模型中的相关变量的影响。
3.动态回归模型
加入了日期以及价格等信息。
名词解释
1.趋势性(trand)
当一个时间序列数据⻓期增⻓或者⻓期下降时,表示该序列有 趋势 。在某些场合,趋势 代表着“转换方向”。例如从增⻓的趋势转换为下降趋势。
2.季节性(season)
当时间序列中的数据受到季节性因素(例如一年的时间或者一周的时间)的影响时,表示 该序列具有 季节性 。季节性总是一个已知并且固定的频率。注意,季节性可能是复合 的。
3.周期性
当时间序列数据存在不固定频率的上升和下降时,表示该序列有 周期性 。这些波动经常 由经济活动引起,并且与“商业周期”有关。
4.滞后
在时间序列中,我们经常会去研究当下时刻的 y**t 和以前的某个数的关系。
y*t−*k 称为
y**t 的 k 阶滞后,记为
lag。
5.自相关
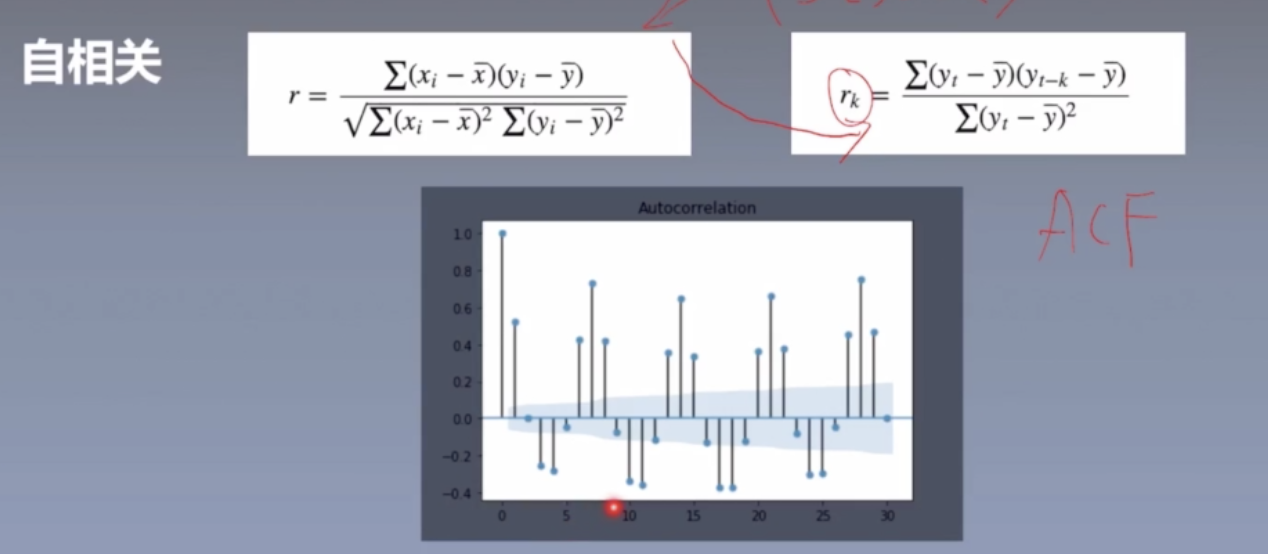
$r_k$ 表示的是 $y_t$ 和他的 k 阶滞后的相关程度。 $r_k$ 称为 ACF (Autocorrelation Coefficient)
通过分析可以看到t和t-7,以及t-14相关性较高。随着时间的远离,相关性会降低。
6.偏相关性
我们有时候需要排除掉这种间接的关系。想去研究 y**t 和
y*t−*k 是否有直接的关系。这个就是偏自相关性。
7.平稳性
是一个前提的假设条件。
这个定理就是时间序列遍历性定理。所以如果一条时间序列满足遍历性,我们就可以通过 对一条轨道在时间上有限样本来估计一些性质。那如何保证时间序列具有遍历性呢? 那 就是这条时间序列是平稳的,且任意两点的相关性随着间隔的⻓度会逐渐降低。
简单点说,平稳的时间序列的性质不随观测时间的变化而变化,比如方差和均值。 所以平稳的时间序列,一定是没有趋势和季节性的。
判断时间序列平稳的方法有两种,一种是通过看图大概判断。一种是严格的通过统计方法 来判别。
1.看原始时序图,看acf和pacf的图,相关性会快速下降到0附近。
2.单位根检验
p 值。p 越小代表代表我们拒绝原假设,那么该时间序列就越该平稳(一般 是threshold 取0.05 或者0.01)
8.白噪声
对所有时间其自相关系数为零的随机过程
2.简单规则模型
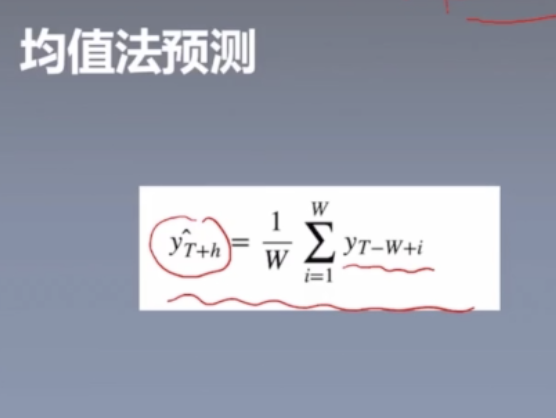
###均值法预测
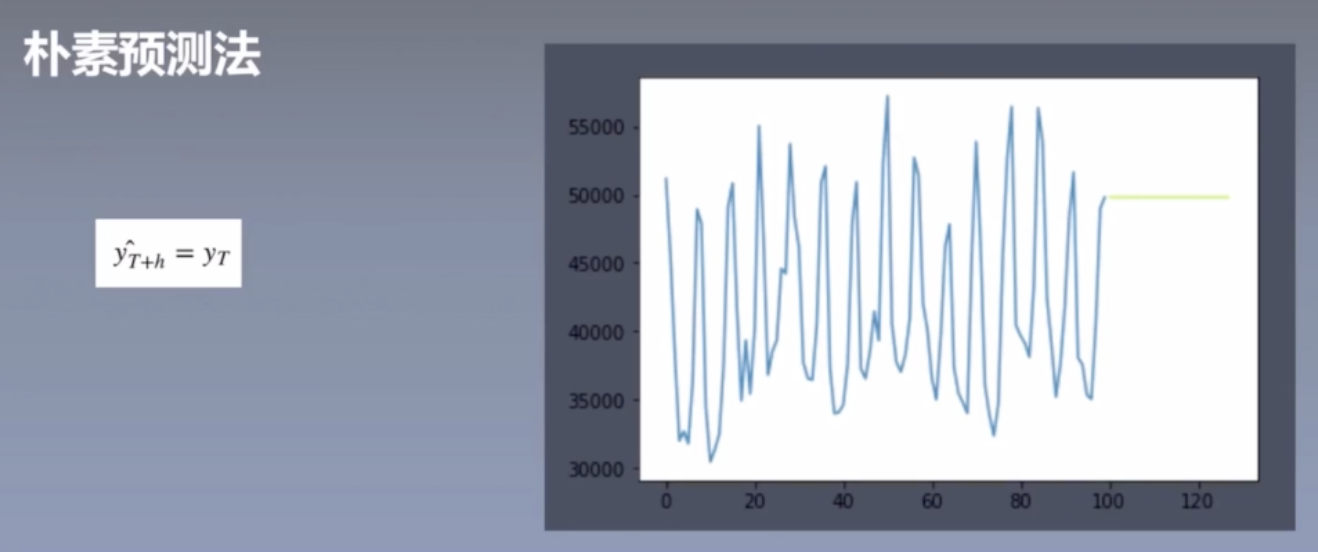
###朴素预测法
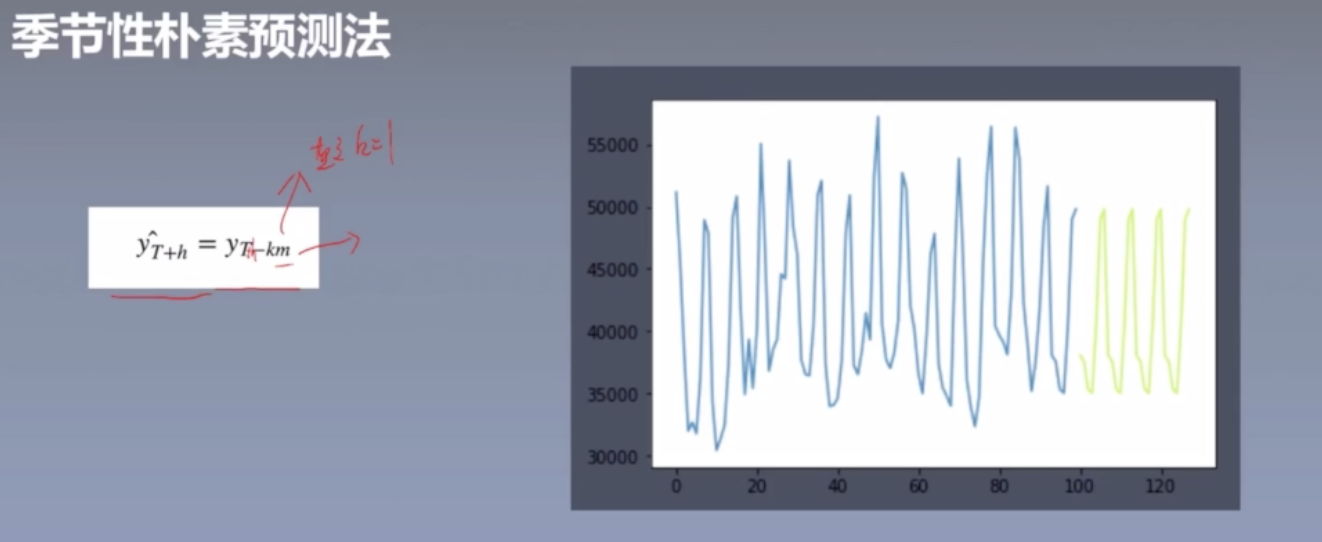
季节性朴素预测法
飘移法
我们考虑到时间序列具有趋势性。
数据调整
考虑到其他的因素影响,通货膨胀、人口增长
3.时间序列分解
当我们想要把时间序列分解为多个成分时,我们通常将趋势和周期组合为“趋势-周期”项 (有时也简单称其为趋势项)。因此,我们认为时间序列包括三个成分:趋势-周期项, 季节项和残差项(残差项包含时间序列中其它所有信息)。
后面我们假设处理的都是加法模型。
首先估计出趋势周期项
将原始时间序列减去趋势周期项
估计季节项
如何估计出趋势周期项?
移动平均估计趋势
$$
\hat{y}{t}=\frac{1}{m} \sum{i=-k}^{k} y_{t+k}
$$
m 为窗口的大小,是为一个奇数 m = 2k + 1。
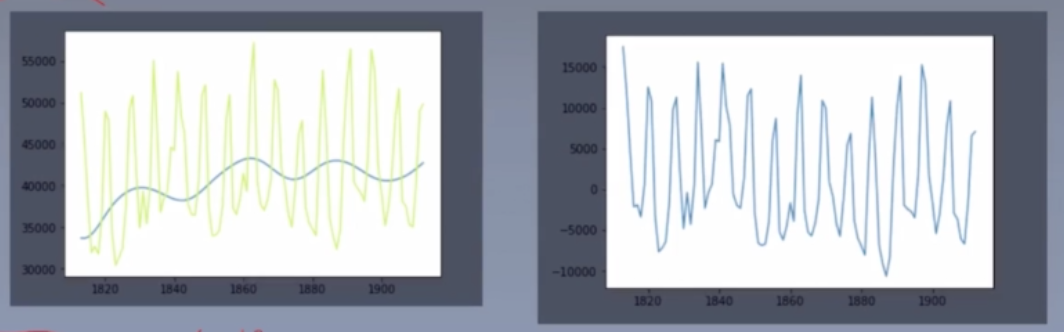
STL时间序列分解
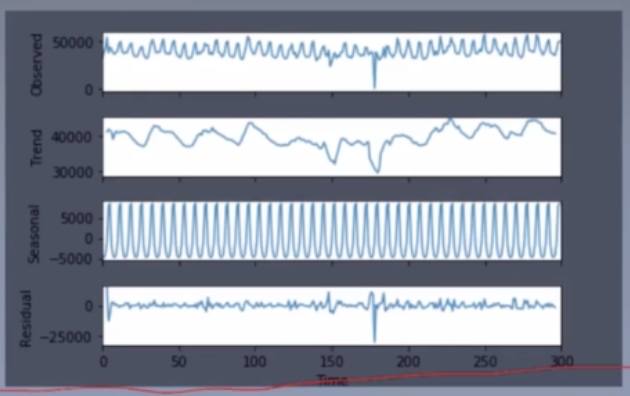
就是分解成趋势、周期(季节)和残差。
用得分来度量趋势和季节程度。(启发:将时间序列划分成两个部分,并分别来进行训练)
4.指数平均模型
这就是一种加权的移动平均模型。就是离当下时刻越远,则他的权重就越小。
一阶指数平滑模型
预测
二阶指数平滑模型
趋势
三阶指数平滑模型
季节
三阶指数模型就是出名的 holt-winter 模型。这个模型可以考虑时间序列的趋势,季节 性。是一个很常用的指数模型。
5.自回归建模
最出名的自回归模型就是 ARIMA 模型。前提条件是时间序列是弱平稳的。
AR(auto correlation)模型
$$
y_{t}=c+\phi_{1} y_{t-1}+\phi_{2} y_{t-2}+\cdots \phi_{p} y_{t-p}+\epsilon_{t}
$$
基于目标变量历史数据的组合对目标变量进行预测。
MA(moving average)模型
$$
y_{t}=c+\epsilon_{t}+\theta_{1} \epsilon_{t-1}+\theta_{2} \epsilon_{t-2}+\theta_{3} \epsilon_{t-3} \cdots \theta_{q} \epsilon_{t-q}
$$
通过历史的误差来建立一个类似回归的模型。
ARIMA模型
ARIMA 模型就是把 AR 模型和 MA 模型合起来,并通过差分的方式,使得不平稳的时间
序列变平稳。( I 表示 Integrated 在这里指差分的逆过程)。
$$
y_{t}=c+\phi_{1} y_{t-1}+\phi_{2} y_{t-2}+\cdots \phi_{p} y_{t-p}+\epsilon_{t}+\epsilon_{t}+\theta_{1} \epsilon_{t-1}+\theta_{2} \epsilon_{t-2}+\theta_{3} \epsilon_{t-3} \cdots \theta_{q} \epsilon_{t-q}
$$
以上模型称为 ARIMA 模型,简记为 ARIMA(p, d, q), p 表示 AR 部分的阶数。 q 表示
MA 部分的阶数。 d 表示差分的阶数。 构建 ARIMA 模型的三个步骤:
做差分,使得时间序列平稳 估计阶数 p 和 q 训练模型,学习参数
通过 acf 和 pacf 可以快速的确定 p 和 q。
缺点:无法做季节性检测
SARIMA模型
引入季节性。
6.层次时间序列
所谓层次时间序列,是指我们有很多的底层的时间序列。这些底层的时间序列可以通过聚 合,形成一个层次结构。
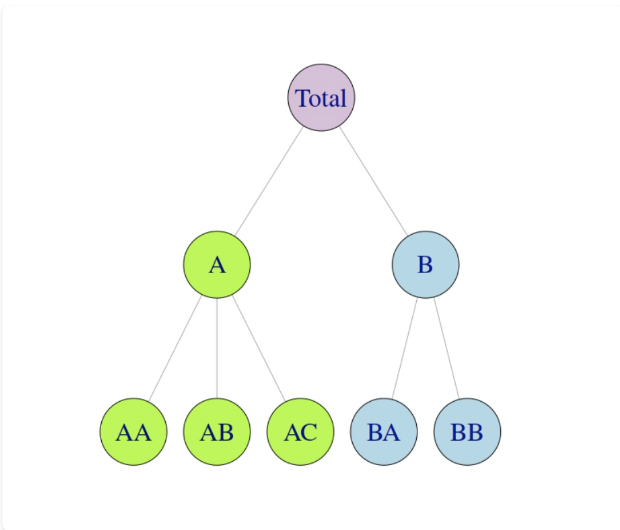
这次的M5就是一个层次时间序列
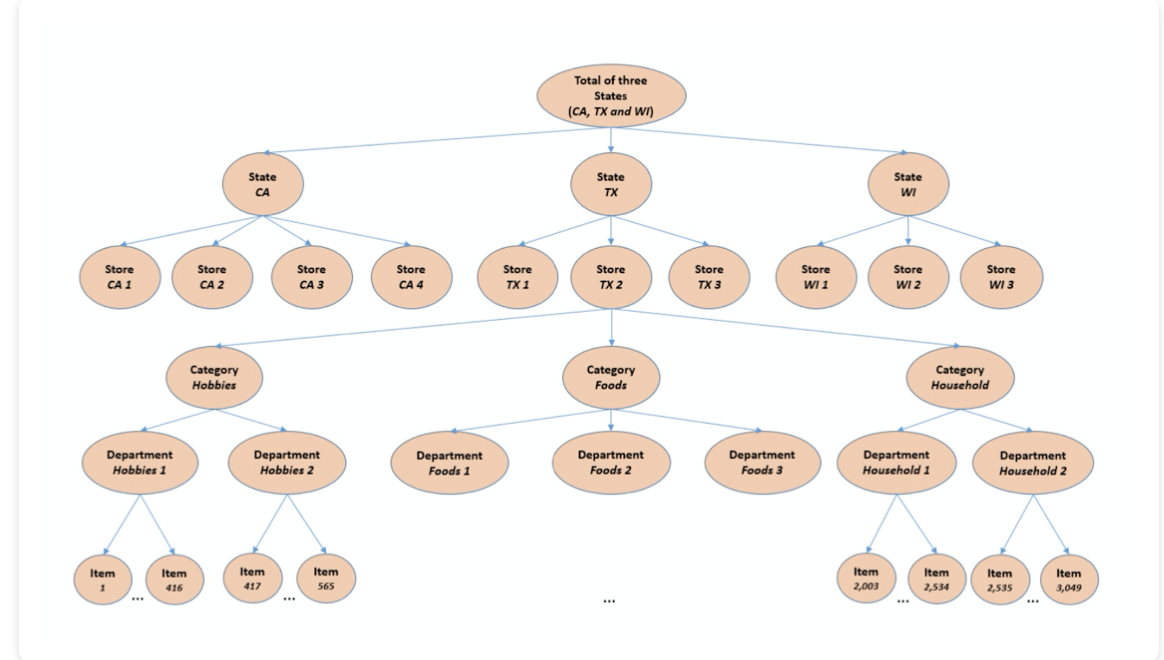
下面是一种快速聚合的方法。

三种预测方案:
1.自下而上的预测
核心在于预测准每一条底层的时间序列。
2.自上而下的预测
我们得到聚合的时间序列(全部聚合得到一条),并对该时间序列进行预测 建模。将预测的值通过某种方式分配给底层的时间序列。根据分配方式的不同,有不同的 实现方案。
如何分配?
使用历史平均比例。
通过遍历历史值,得到每一条底层时间序列占这条总的时间序列的比值。
对分配比例进行预测
通过模型,去预测底层时间序列占这条总的时间序列比值的变化情况。
3.自中向上下的预测
我们可以选择一个中间聚合的时间序列进行预测。比如按店 铺,甚至是按商品品类。因为过多的聚合,会导致信息的丢失,所以我们可以选择一个中 间层次的聚合时间序列进行预测,然后自上自下进行展开预测。
enlighten
将样本分别预测,也就是用不同的模型去预测不同的样本。这其实有点投机取巧了,但是为了提高分数,这没什么不可以的。那我觉得可以针对每一个样本计算它的趋势。也就是趋势是和每一个样本相关的。有30490个样本,那么就有30490个趋势。这个参数是与样本有关的。就和2s-AGCN中的动态图一样。(用样本数据计算得到的)。
