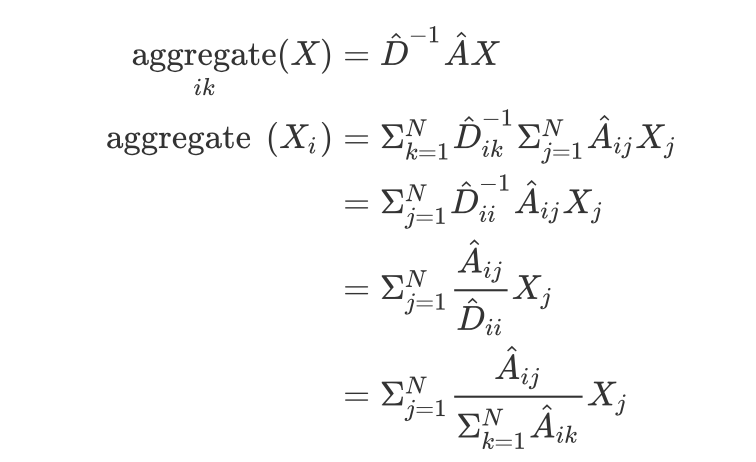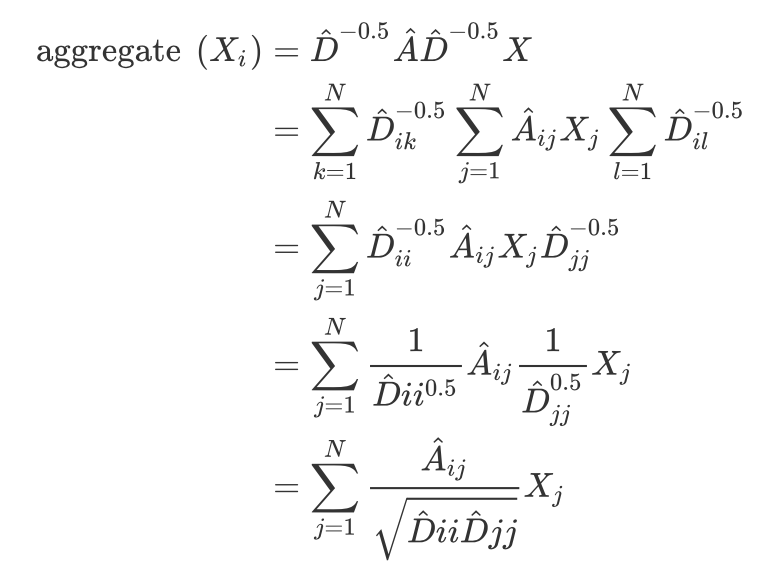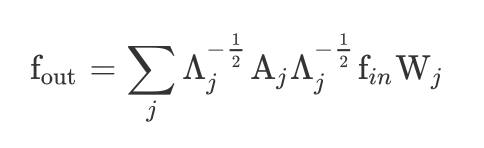基本上把牛客网的华为机试题做完了,总结了一些在做题过程中收集的知识点。
1.处理输入数据的框架:
1 | while True: |
2.常用的数据结构:
| 数据结构 | 添加 | 删除 | 生成 |
|---|---|---|---|
| list | append() | pop() | [] |
| set | add() | remove() | set() |
| dict | d[‘x’] | pop(key) | dict() |
有个字典挺好用的,在统计数量上有奇效。它设有默认值。
1 | from collections import defaultdict |
3.字符串的操作:
参考:https://www.runoob.com/python/python-strings.html
比较常用的说一下:
in 操作符 如果字符串包含给定的字符返回True
string.join(seq)以string作为分隔符,将seq中所有的元素合并为一个新的字符串。
count 返回str在string里面出现的次数
find 检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1
isalnum 如果至少有一个字符并且所有字符都是字母或者数字则返回True
isalpha 如果至少有一个字符并且所有字符都是字母则返回True
Isupper 如果是大写返回True
islower 如果是小写返回True
isdigit如果至少有一个字符并且所有字符都是数字则返回True
max 返回字符串最大的字母
min 返回字符串最小的字母
%s 是一种字符串格式化的语法,基本用法就是将值入到%s占位符的字符串中。%s表示格式化一个对象为字符
1 | string = "good" #类型为字符串 |
r’ ‘ 告诉系统不需要转义,就是直接的这个字符串。不涉及到转义字符。
统计字符串的字母的个数:
1 | from collections import Counter |
4.ASCII字符转换
ord()字符转换成ASCII值
chr()ASCII值转换成字符
5.range的倒序遍历:
range(start,end-1,-1) # range(9,-1,-1)
6.自定义排序
注意,这里使用的条件是数组,不是字符串。
1 | o |
默认是函数值从小到大排序
7.数值精度
例如:result为一个list,为result中每个值保留4位。result = [("%.4f" % i) for i in result]
8.字节的长度:
GBk 中文两个字节
UTF 中文三个字节
查看不同编码下的字节长度:
1 | len(i.encode('gbk')) # 'gbk','utf8' |
9.print(a,b)是自带空格的,输出为:a b
10.二维数组和一维数组其实差不多。
11.定义一个新的结构体:(链表,数的结点等)
1 | class Node(object): |
12.判断一个数是否是质数:
1 | 链接:https://www.nowcoder.com/questionTerminal/f8538f9ae3f1484fb137789dec6eedb9 |
13.排列与组合:
组合用combinations
排列用permutations
1 | form itertools import combinations, permutations |
14.输出一个矩阵
1 | # 这里的矩阵是 |
15.参数改变的问题
参考:https://www.cnblogs.com/monkey-moon/p/9347505.html
不想改变的话用copy.deepcopy(a)
16.位移
1 | a = a >> 1 |
17.字符串格式化
方法一:format函数
1 | >>> print('{:.3f}'.format(1.23456)) |
format有不同用法,前者使用了占位符{},使用占位符可以同时输出多个,后者一次只能输出一个,需要注意的是占位符中的冒号不能丢。推荐使用占位符+format输出。
1 | >>> print('{:.3f} {:.2f}'.format(1.23456, 1.23456)) |
方法二:’%.xf’方法
1 | >>> print('%.2f' % 1.23456) |
18.字典的遍历:
(1)遍历key值
1 | >>> a |
(2)遍历value
1 | >>> for value in a.values(): |
(3)遍历字典项
1 | >>> for key,value in a.items(): |
(4)按一定的顺序遍历字典项:
1 | # 按key排序 |